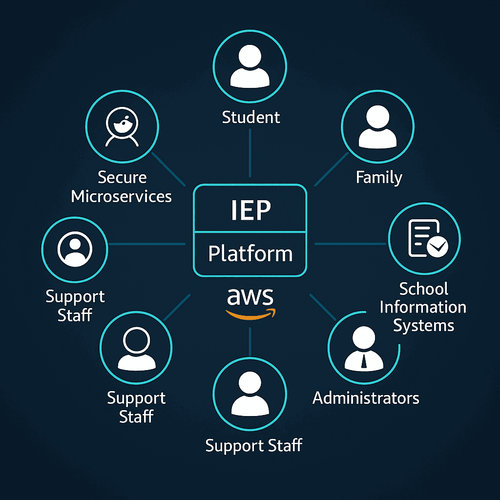
Delivering Trustworthy Legal Precedents with Agentic RAG
KnowTech.ai
Read morearrow_right_altFrom structured knowledge assets to AI-powered reasoning — we engineer the intelligence layer that makes enterprise platforms trustworthy, discoverable, and cognitively aware.

Researchers and engineers waste hours searching fragmented repositories. We build AI systems that understand intent, synthesize across millions of documents, and surface the most relevant, trusted answers — fast. From engineering data platforms serving 170+ content providers to legal research tools that cut case preparation time in half, we turn siloed knowledge into competitive advantage. Our solutions combine semantic search, RAG, and domain-specific AI to deliver results your teams can act on — with full citations and audit trails.
Universities and R&D organizations struggle to unify faculty data, research output, and institutional repositories into a coherent system. We design and deliver end-to-end Research Information Management platforms — integrating Interfolio, Digital Commons, Scopus, and custom repositories into a single intelligent ecosystem. Our solutions support the full research lifecycle: faculty hiring, promotion workflows, open-access publishing, analytics dashboards, and AI-assisted discovery — helping institutions demonstrate research impact and stay accreditation-ready.
Legacy content, unstructured documents, and siloed data are holding your AI strategy back. We transform raw enterprise knowledge into structured, AI-ready assets — building taxonomies, ontologies, and enriched metadata pipelines that become the foundation for intelligent search, RAG, and knowledge graph applications. Whether you're modernizing a content platform, migrating to the cloud, or preparing your knowledge base for GenAI, we deliver the structured intelligence layer that makes every downstream AI application more accurate and trustworthy.
We design and implement hybrid search architectures combining keyword, vector, and AI reranking across Elasticsearch, Solr, Vespa, and OpenSearch. Our approach covers query understanding, synonym management, faceted navigation, and A/B relevance testing — with dashboards your team owns. We tune for precision and recall specific to your domain, integrating spell correction, semantic expansion, and boosting rules. Every deployment includes documentation, CI pipelines, and playbooks so your engineers can iterate independently after go-live.
We build production knowledge graphs on Neo4j, AWS Neptune, and RDF triple stores — with AI-assisted entity resolution, deduplication, and lineage tracking at every stage. Our pipelines run on Airflow, Spark, and dbt, moving data from heterogeneous sources into governed, queryable knowledge structures. We deliver data contracts, API layers, and schema governance so your teams have a reliable, versioned foundation for downstream AI and analytics. Graph-based queries unlock relationship insights no relational database can surface.
We deploy retrieval-augmented generation systems grounded in your verified knowledge corpus — not generic LLM outputs. Our RAG implementations use hybrid retrieval, intelligent chunking, cross-encoder reranking, and prompt guardrails to minimize hallucinations. Built on LangChain, LlamaIndex, and Pinecone with your choice of foundation model — Claude, GPT-4, Gemini, or Mistral — every assistant includes citation linking, PII filtering, and audit logging. We run evals throughout to measure answer quality and improve grounding post-deployment.
Excellent work, everyone! The deadline was tight, but it’s truly gratifying to see this progress happening!

Lars Bo Spring
VP Engineering , A&G Technology
Denmark EU
Just wanted to say thanks for all your hard work getting STEP/EVA moved to the new production environment. I know the timeline was tight, but you guys made it happen. Really appreciate all your effort on this one. Great foundation to build on – can’t wait to see what’s next! Thanks again
Carlos Fonseca
Director of Engineering, SciVal
Haarlem Netherlands EU
There were many new tools and technologies to explore and project had a very aggressive timeline, and Sysvine rose to the challenge, delivered the project on time and exceeded all set expectations…

Chi Yeung Cheung
Senior Vice President DSI , NPD
Port Washington NY US
From structured knowledge assets to AI-powered reasoning — we engineer the intelligence layer that makes enterprise platforms trustworthy, discoverable, and cognitively aware.
Researchers and engineers waste hours searching fragmented repositories. We build AI systems that understand intent, synthesize across millions of documents, and surface the most relevant, trusted answers — fast. From engineering data platforms serving 170+ content providers to legal research tools that cut case preparation time in half, we turn siloed knowledge into competitive advantage. Our solutions combine semantic search, RAG, and domain-specific AI to deliver results your teams can act on — with full citations and audit trails.
Universities and R&D organizations struggle to unify faculty data, research output, and institutional repositories into a coherent system. We design and deliver end-to-end Research Information Management platforms — integrating Interfolio, Digital Commons, Scopus, and custom repositories into a single intelligent ecosystem. Our solutions support the full research lifecycle: faculty hiring, promotion workflows, open-access publishing, analytics dashboards, and AI-assisted discovery — helping institutions demonstrate research impact and stay accreditation-ready.
Legacy content, unstructured documents, and siloed data are holding your AI strategy back. We transform raw enterprise knowledge into structured, AI-ready assets — building taxonomies, ontologies, and enriched metadata pipelines that become the foundation for intelligent search, RAG, and knowledge graph applications. Whether you're modernizing a content platform, migrating to the cloud, or preparing your knowledge base for GenAI, we deliver the structured intelligence layer that makes every downstream AI application more accurate and trustworthy.
We design and implement hybrid search architectures combining keyword, vector, and AI reranking across Elasticsearch, Solr, Vespa, and OpenSearch. Our approach covers query understanding, synonym management, faceted navigation, and A/B relevance testing — with dashboards your team owns. We tune for precision and recall specific to your domain, integrating spell correction, semantic expansion, and boosting rules. Every deployment includes documentation, CI pipelines, and playbooks so your engineers can iterate independently after go-live.
We build production knowledge graphs on Neo4j, AWS Neptune, and RDF triple stores — with AI-assisted entity resolution, deduplication, and lineage tracking at every stage. Our pipelines run on Airflow, Spark, and dbt, moving data from heterogeneous sources into governed, queryable knowledge structures. We deliver data contracts, API layers, and schema governance so your teams have a reliable, versioned foundation for downstream AI and analytics. Graph-based queries unlock relationship insights no relational database can surface.
We deploy retrieval-augmented generation systems grounded in your verified knowledge corpus — not generic LLM outputs. Our RAG implementations use hybrid retrieval, intelligent chunking, cross-encoder reranking, and prompt guardrails to minimize hallucinations. Built on LangChain, LlamaIndex, and Pinecone with your choice of foundation model — Claude, GPT-4, Gemini, or Mistral — every assistant includes citation linking, PII filtering, and audit logging. We run evals throughout to measure answer quality and improve grounding post-deployment.
Excellent work, everyone! The deadline was tight, but it’s truly gratifying to see this progress happening!
Lars Bo Spring
VP Engineering , A&G Technology
Denmark EU
Just wanted to say thanks for all your hard work getting STEP/EVA moved to the new production environment. I know the timeline was tight, but you guys made it happen. Really appreciate all your effort on this one. Great foundation to build on – can’t wait to see what’s next! Thanks again
Carlos Fonseca
Director of Engineering, SciVal
Haarlem Netherlands EU
There were many new tools and technologies to explore and project had a very aggressive timeline, and Sysvine rose to the challenge, delivered the project on time and exceeded all set expectations…
Chi Yeung Cheung
Senior Vice President DSI , NPD
Port Washington NY US